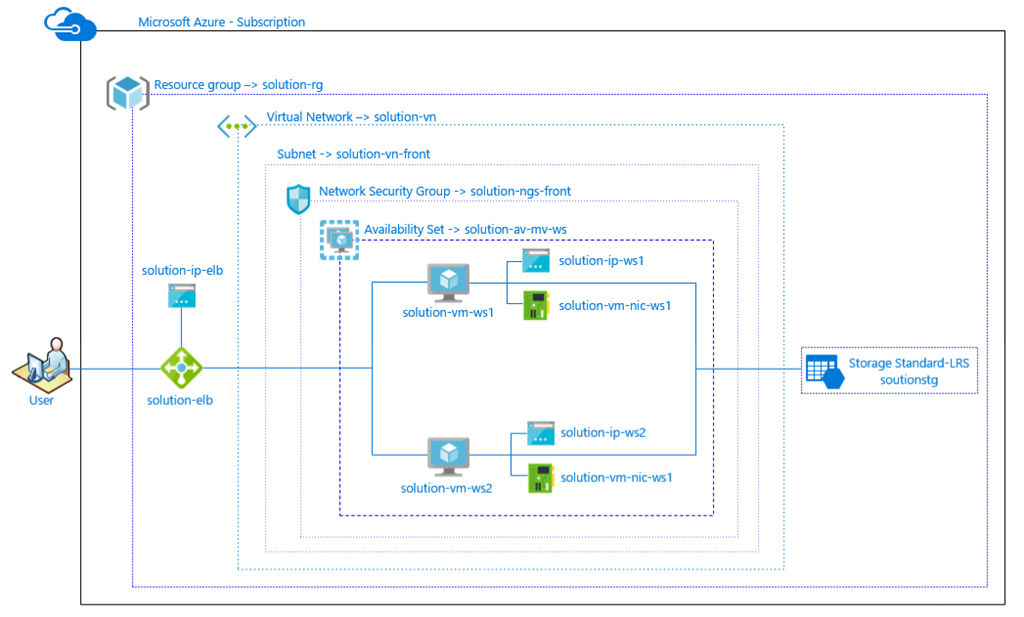
SQL Server es un potente motor de base de datos que aumenta y expande muchas características dándonos fiabilidad, calidad y facilidad de uso. SQL Server constituye un componente clave de una organización que la implementa, donde el servidor contiene datos muy importantes del día a día de la organización. Es por esto que la integridad de los archivos MDF y NDF que hacen parte de nuestra base de datos sea una las principales preocupaciones en la mente de los DBA’s y administración de TI.
Es por esto que en esta oportunidad hablaremos de un excelente producto llamado Stellar Phoenix SQL Database Repair desarrollado por Stellar Information Technology Pvt. Ltd. Este producto nos ayuda a recuperar bases de datos de SQL Server que se encuentren corruptas y restaura todos los objetos inaccesibles o dañados a una nueva base de datos. Ver Figura 1.
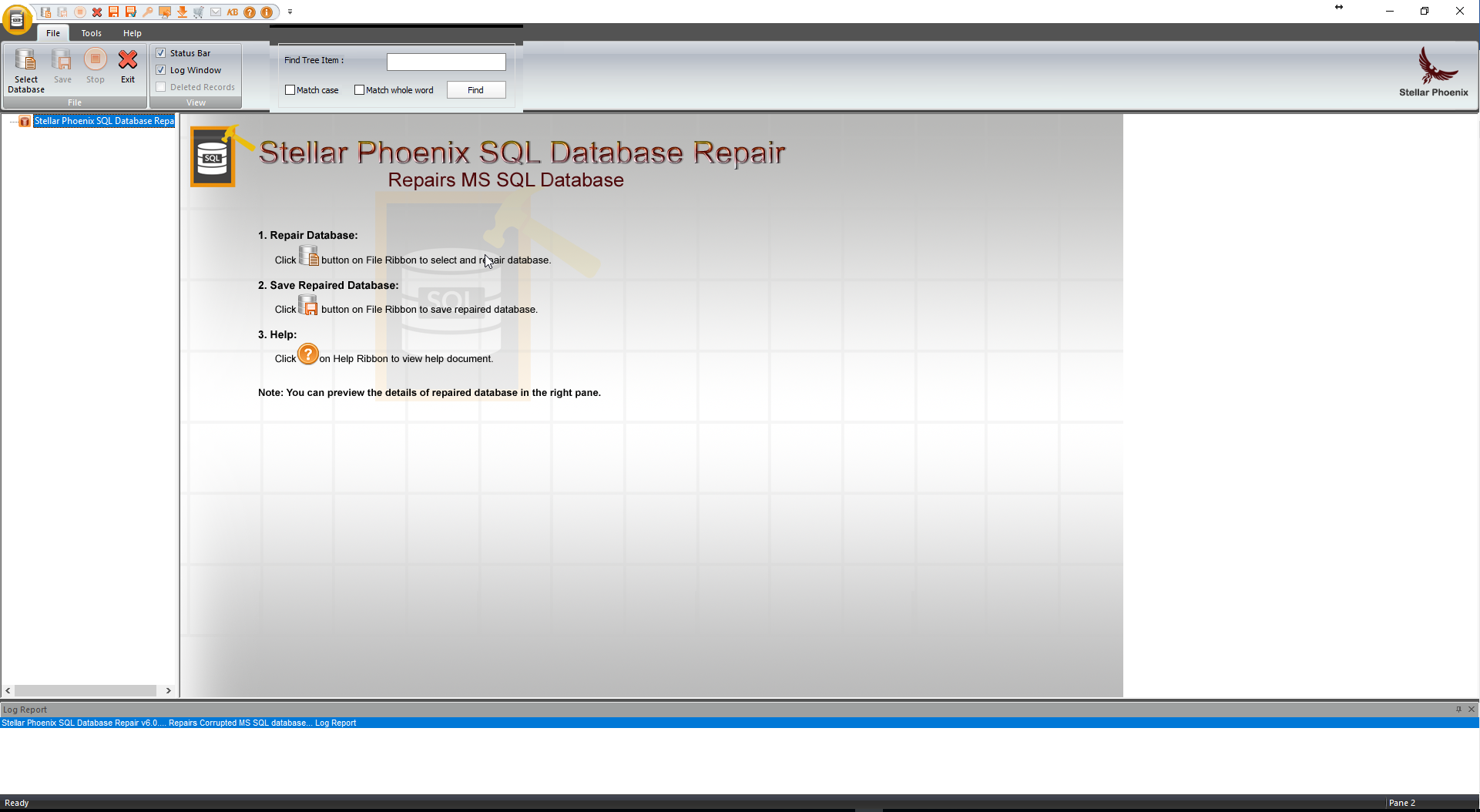
Figura 1. – Stellar Phoenix SQL Database Repair en acción.
Características claves de Stellar Phoenix SQL Database Repair
- Repara los ficheros MDF y NDF de la base de datos de SQL Server cuando la corrupción se debe a un problema en el nivel de subsistema del disco o a una actualización a una versión superior de MS SQL Server.
- Restaura rápidamente todos los objetos inaccesibles de tu base de datos SQL corrupta, como por ejemplo tablas, vistas, índices, procedimientos almacenados, datos XML y datos de secuencias de archivos (para SQL Server 2008).
- Permite la recuperación de una base de datos completa o de cualquier objeto seleccionado.
- En caso de que el software no pueda recuperar algún objeto de la base de datos, ofrecerá la opción de guardar las consultas a esos objetos en un archivo de texto. Con la ayuda de estas consultas, se podrá recrear de nuevo los objetos corruptos con facilidad y usarlos como antes.
- Ofrece vista previa de los objetos de la base de datos que se pueden recuperar. Esta función ayuda a comprobar la eficacia de la aplicación al permitir una verificación sencilla de los resultados del análisis antes de finalizar el proceso de recuperación.
- Ofrece la recuperación de registros borrados de bases de datos corruptas mientras ejecuta la función de reparación, donde a través de una vista preliminar muestra estos registros borrados para que pueda se verificar la precisión de los resultados antes de guardar.
- Ofrece múltiples opciones de guardado en los siguientes formatos: MSSQL, CSV, HTML y XLS.
- Ofrece recuperación de datos comprimidos PAGE como los datos comprimidos ROW de la base de datos SQL. Esta aplicación también es compatible con el Esquema de Compresión Estándar para Unicode (Standard Compression Scheme for Unicode/SCSU) en SQL Server 2008 R2.
- La aplicación es capaz de reparar y restaurar las nuevas secuencias de esquemas definidas por el usuario en SQL Server 2016 y las ediciones anteriores 2014, 2012, 2008 R2, 2008, 2005, 2000 y 7.0.
Instalación
Una vez descargado el trial o comprado el producto, procedemos a instalar el producto. Ejecutamos el archivo instalador StellarPhoenixSQLDatabaseRepair, donde nos muestra la pantalla de bienvenida y damos click en siguiente. Ver Figura 2.

Figura 2. – Pantalla de bienvenida instalador de Stellar Phoenix SQL Database Repair.
A continuación leemos el acuerdo de licenciamiento, aceptamos el acuerdo y damos click en siguiente. Ver Figura 3.
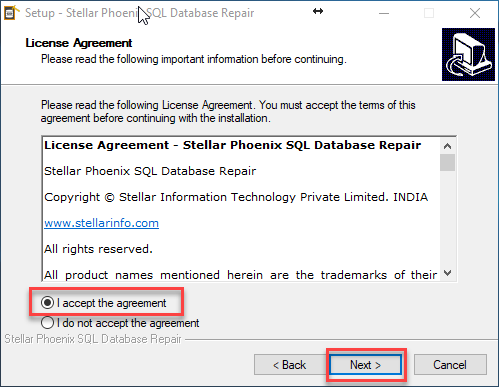
Figura 3. – Acuerdo de licenciamiento de Stellar Phoenix SQL Database Repair.
Posteriormente seleccionamos la ubicación donde queremos instalar el software, en este caso seleccionamos la ubicación por defecto y damos click en siguiente. En esta pantalla en la parte de abajo nos hace una advertencia de que se necesitan al menos 15 MB de espacio en el disco duro para poder instalar el software. Ver Figura 4.
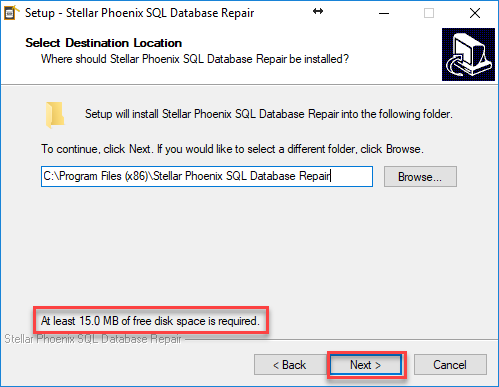
Figura 4. – Acuerdo de licenciamiento de Stellar Phoenix SQL Database Repair.
Posteriormente nos pide que configuremos la carpeta del menú inicio donde pondrá los accesos directos de la aplicación, en este caso dejamos por defecto la que nos muestra el instalador y damos click en siguiente. Ver Figura 5.
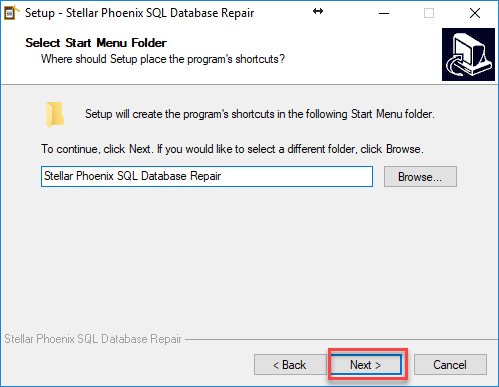
Figura 5. – Acuerdo de licenciamiento de Stellar Phoenix SQL Database Repair.
Ahora nos pide que seleccionemos que tareas adicionales que deseemos para la configuración del proceso de instalación, que son la de crear un icono en el escritorio o un icono de lanzamiento rápido y damos click en siguiente. Ver Figura 6.
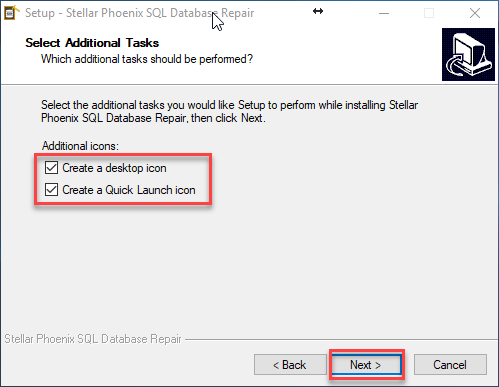
Figura 6. – Tareas adicionales en la instalación de Stellar Phoenix SQL Database Repair.
Por último nos muestra el resumen de la configuración de la instalación, damos click en Instalar. Ver Figura 7.

Figura 7. – Resumen configuración de la instalación de Stellar Phoenix SQL Database Repair.
Ahora inicia la instalación del software. Ver Figura 8.
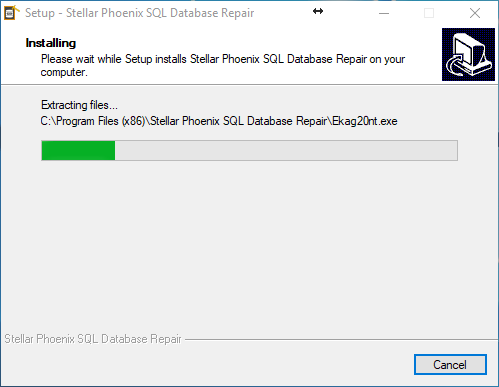
Figura 8. – Instalación de Stellar Phoenix SQL Database Repair.
Con esto finaliza el proceso de instalación del software de recuperación de Stellar Phoenix SQL Database Repair.
Corrupción de la base de datos
Una vez instalado el software procedemos a ejecutarlo. Ahora quiero mostrarles cómo funciona este software y cómo podemos recuperar una base de datos SQL Server cuando el (los) archivo(s) MDF y/o NDF se encuentra(n) corrupto(s). En este momento no cuento con una base de datos corrupta, y es cuando nos preguntamos cómo podemos corromper una base de datos dañando intencionalmente el archivo MDF ó NDF para poder probar el software y ver que realmente funciona.
Existen algunos métodos para corromper el archivo MDF o NDF, uno de ellos es utilizar un software de edición hexadecimal como HxD ó XVI32 (Ver Figura 9 y 10), donde realizamos las siguientes instrucciones:
- Desajuntamos la base de datos del motor de SQL Server
- Abrimos el editor hexadecimal de nuestra preferencia y cargamos el archivo MDF de la base de datos que queremos corromper.
- En el editor hexadecimal modificamos el archivo cambiando valores y guardando estos cambios para que se convierta en corrupta.
- Adjuntamos la base de datos nuevamente en el motor de SQL Server.
- Ejecutamos el comando DDBC CHECKDB para corroborar si la base de datos esta corrupta.
Otra opción es usar el comando DBCC WRITEPAGE que permite cambiar cualquier byte en la página de datos y de esta manera corrompe el archivo MDF. Este comando se encuentra disponible desde la versión 2000 de SQL Server. Como bien sabemos la página es la unidad fundamental del almacenamiento de datos en SQL Server y su tamaño es de 8 KB.
Debemos aclarar que el comando DBCC WRITEPAGE es considerado por muchos expertos como el comando más peligroso de SQL Server, como será que si buscan información de este comando en MSDN o TechNet, Microsoft no lo tiene documentado por lo peligroso que puede ser, inclusive Paul Randal considera que es uno de los principales secretos existentes en SQL Server. Los únicos que utilizan este comando son expertos de Microsoft con nivel de Dios de SQL Server, de lo contrario nadie por ningún motivo debe usar este comando y menos en ambientes de producción. Este comando lo utilizare únicamente en modo ejemplo para poder comprobar que el software Stellar Phoenix SQL Database Repair nos ayuda a recuperar nuestras bases de datos cuando estas se encuentran corruptas.
Iniciaremos creando una base de datos muy sencilla con dos tablas relacionadas:

Figura 11. – Tablas de la base de datos a crear.
Ejecutamos el siguiente script en SQL Server:
USE master
GO
-- Si existe la base de datos se elimina
IF EXISTS(select * from sys.databases where name='Geography')
DROP DATABASE GeographyDB
GO
-- Se crea la Base de datos
CREATE DATABASE GeographyDB
GO
--Usamos la base de datos Geography
USE GeographyDB
GO
-- Se crea la tabla Country
CREATE TABLE [dbo].[Country](
[IdCountry] [int] NOT NULL,
[CountryName] [nvarchar](100) NULL,
[CountryCode] [char](2) NULL,
CONSTRAINT [PK_Country] PRIMARY KEY CLUSTERED
(
[IdCountry] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
-- Se crea la tabla City
CREATE TABLE [dbo].[City](
[IdCity] [int] NOT NULL,
[IdCountry] [int] NULL,
[CityName] [nvarchar](100) NULL,
[FoundationYear] [int] NULL,
[Population] [int] NULL,
[Area] [decimal](18, 2) NULL,
[Elevation] [int] NULL,
CONSTRAINT [PK_City] PRIMARY KEY CLUSTERED
(
[IdCity] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
-- Se adiciona la llave foránea entre las tablas Country y City
ALTER TABLE [dbo].[City] WITH CHECK ADD CONSTRAINT [FK_City_Country] FOREIGN KEY([IdCountry])
REFERENCES [dbo].[Country] ([IdCountry])
GO
ALTER TABLE [dbo].[City] CHECK CONSTRAINT [FK_City_Country]
GO
-- Insertamos información en la tabla Country
INSERT INTO [dbo].[Country] VALUES (1,'United States', 'US');
INSERT INTO [dbo].[Country] VALUES (2,'Colombia', 'CO');
INSERT INTO [dbo].[Country] VALUES (3,'Argentina', 'AR');
INSERT INTO [dbo].[Country] VALUES (4,'Brasil', 'BR');
INSERT INTO [dbo].[Country] VALUES (5,'Peru', 'PE');
-- Verificamos los registros de la tabla Country
SELECT * FROM [GeographyDB].[dbo].[Country];
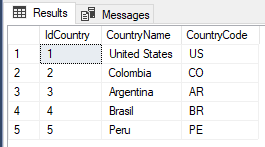
Figura 12. – Registros en la tabla Country
-- Insertamos información en la tabla City
INSERT INTO [dbo].[City] VALUES (1,1,'Chicago',1837,2722389,606.10,182);
INSERT INTO [dbo].[City] VALUES (2,1,'New York',1624,8550406,1214.00,10);
INSERT INTO [dbo].[City] VALUES (3,1,'Miami',1825,417650,145.21,2);
INSERT INTO [dbo].[City] VALUES (4,2,'Bogota',1538,8080734,1775.00,2600);
INSERT INTO [dbo].[City] VALUES (5,2,'Medellin',1616,2508452,382.00,1495);
INSERT INTO [dbo].[City] VALUES (6,2,'Cali',1536,2450013,619.00,1018);
INSERT INTO [dbo].[City] VALUES (7,3,'Buenos Aires',1536,2890151,230.00,25);
INSERT INTO [dbo].[City] VALUES (8,4,'Rio de Janeiro',1565,6476631,1182.00,11);
INSERT INTO [dbo].[City] VALUES (9,4,'Sao Paulo',1554,11967825,1522986.00,760);
INSERT INTO [dbo].[City] VALUES (10,5,'Lima',1535,10852210,2672.00,154)
-- Verificamos los registros de la tabla Country
SELECT * FROM [GeographyDB].[dbo].[City];
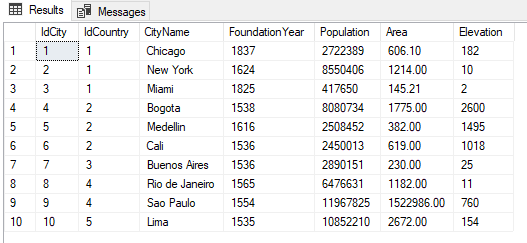
Figura 13. – Registros en la tabla City
Para identificar una página especifica que podamos corromper, podemos utilizar el comando DBCC IND que también se encuentra indocumentado. El comando DBCC IND funciona con los siguientes parámetros DBCC IND ( {dbname}, {table_name},{index_id} ).
En este caso, en el parámetro index_id tomamos el 1 que indica un índice clustered y que existe en nuestro modelo.
Al ejecutar este comando se generará una descripción de las páginas que componen nuestro índice agrupado de nuestra tabla City.
Ejecutamos el siguiente script:
-- Muestra un resumen de páginas para el índice clustered en la tabla City (índice id = 1)
DBCC IND (GeographyDB, 'City', 1)
GO
En este caso buscamos la primera página donde el PageType es 1 (página de datos), por lo que nos da un PageId con valor de 336. Ver Figura 14.

Figura 14. – Registros en la tabla Country
Ahora ejecutamos el comando peligro de DBCC WRITEPAGE que contiene la siguiente estructura:
DBCC WRITEPAGE ({dbname | dbid}, fileid, pageid, offset, longitud, data [, directORbufferpool])
En el parámetro directOrBufferpool si pasamos un 0 quiere decir que los datos se guardarán en el grupo de búfer antes de ser guardados en el disco, pero si pasamos un 1 el valor de los datos se escribirá directamente en el disco sin ninguna oportunidad de crear una suma de comprobación válida para la página. Este enfoque es mucho más similar a tener un editor hexadecimal y hacer una edición directa en el archivo de datos.
-- Corrompemos la página de datos
ALTER DATABASE GeographyDB SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DBCC WRITEPAGE('GeographyDB', 1, 336, 60, 1, 0x00, 1)
Debido a que en nuestro ejemplo hemos proporcionado 1 como nuestro valor de directOrBufferpool, nuestro cambio se realizó directamente en el archivo en disco, lo que significa que la suma de comprobación ó checksum en la página es casi seguramente errónea. Podemos comprobar esto haciendo un select directa de la tabla. Esto hará que la página de datos se vuelva a leer en la memoria, lo que a su vez hará que se compruebe la suma de comprobación o checksum.
-- Verificamos los registros de la tabla Country
SELECT * FROM [GeographyDB].[dbo].[City];
Nos muestra como resultado:
Msg 824, Level 24, State 2, Line 85
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x670d0a00; actual: 0x670d0ab0). It occurred during a read of page (1:336) in database ID 10 at offset 0x000000002a0000 in file ‘C:Program FilesMicrosoft SQL ServerMSSQL13.SQL2K16MSSQLDATAGeographyDB.mdf’. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
Ahora ejecutamos el comando DBCC CHECKDB para comprobar la integridad lógica y física de todos los objetos de la base de datos.
-- Verificamos la integridad de la base de datos
DBCC CHECKDB (GeographyDB)
GO
En el resultado de este comando en una parte del mensaje nos muestra el siguiente error:
Msg 8939, Level 16, State 98, Line 89
Table error: Object ID 597577167, index ID 1, partition ID 72057594041335808, alloc unit ID 72057594046971904 (type In-row data), page (1:336). Test (IS_OFF (BUF_IOERR, pBUF->bstat)) failed. Values are 133129 and -4.
Msg 8928, Level 16, State 1, Line 89
Object ID 597577167, index ID 1, partition ID 72057594041335808, alloc unit ID 72057594046971904 (type In-row data): Page (1:336) could not be processed. See other errors for details.
Msg 8980, Level 16, State 1, Line 89
Table error: Object ID 597577167, index ID 1, partition ID 72057594041335808, alloc unit ID 72057594046971904 (type In-row data). Index node page (0:0), slot 0 refers to child page (1:336) and previous child (0:0), but they were not encountered.
Este resultado nos confirma que la Base de Datos esta corrupta, en este caso hace referencia al PartitionID 72057594041335808 que podemos verificar en la Figura 12 que corresponde a la página de datos que corrompimos.
Recuperación de la base datos SQL Server
Ya tenemos el escenario perfecto para probar el software Stellar Phoenix SQL Database Repair con una base de datos corrupta. Ahora ejecutamos el software.
Lo primero que muestra el software cuando lo ejecutamos es un mensaje informativo diciendo que detengamos el servicio de SQL Server, saquemos una copia del archivo de base de datos y la pongamos en una ubicación diferente a la original, iniciemos el servicio de SQL Server y reparemos la copia. Damos click en el botón OK. Ver Figura 15.
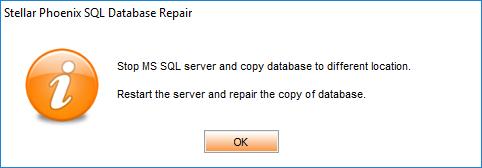
Figura 15. – Mensaje Informativo.
En este caso seguimos estos pasos, donde creamos una carpeta llamada BDCorruptas (“C:BDCorruptas”) y acá pegamos la copia de la base de datos corrupta. Ver imagen 16.
Figura 16. – Copia de la base corrupta en una ubicación diferente.
La pantalla de inicio del software nos muestra un mensaje bastante claro con los pasos a seguir para restaurar una base de datos corrupta. Ver Figura 17.

Figura 17. – Mensaje pantalla de inicio.
Seleccionamos el archivo MDF que se encuentra corrupto y queremos reparar. Si conocemos la ruta simplemente seleccionamos la base de datos desde su ubicación, pero en caso que no recordemos el nombre del archivo podemos hacer una búsqueda de los archivos MDF en una ubicación específica y damos click en el botón Reparar. Ver Figura 18.
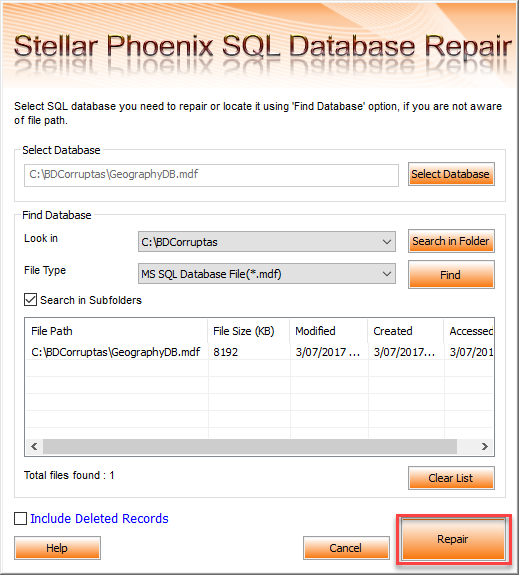
Figura 18. – Selección de la base de datos a reparar.
Nos pregunta el software en cual versión de SQL Server se encuentra el archivo de base de datos que vamos reparar. En nuestro caso se encuentra en SQL Server 2016 donde seleccionamos la opción de “MS SQL Server 2012 or Server 2014 or Server 2016”. Damos click en OK. Ver Figura 19.
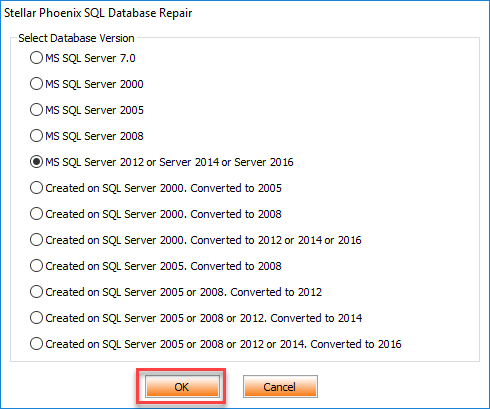
Figura 19. – Selección de la versión de la base de datos a reparar.
El software empieza a realizar el respectivo análisis y reparación de la base datos. Finalmente nos muestra un mensaje donde la base de datos fue repara exitosamente. Ver Figura 20.
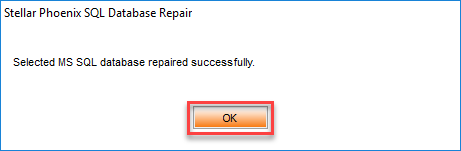
Figura 20. – Mensaje reparación exitosa.
Una vez reparada la base de datos podemos ver en la parte de abajo del software un log paso a paso de la ejecución del proceso de reparación. Ver Figura 21.
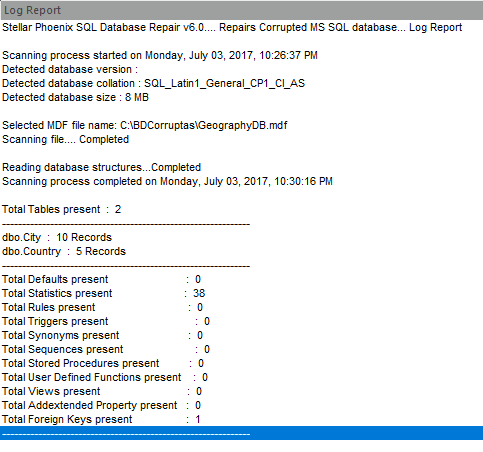 Ver Figura 21. – Log de ejecución proceso de reparación.
Ver Figura 21. – Log de ejecución proceso de reparación.
En la parte de arriba del software nos muestra un explorador de objetos que contiene el archivo MDF, donde podemos ver tablas, vistas, índices, procedimientos almacenado, funciones. En este caso vamos a dar click en la tabla City y podremos observar que el software nos recuperó la información de esta tabla, después de que dañamos la página de datos correspondiente a esta tabla. Ver Figura 22.
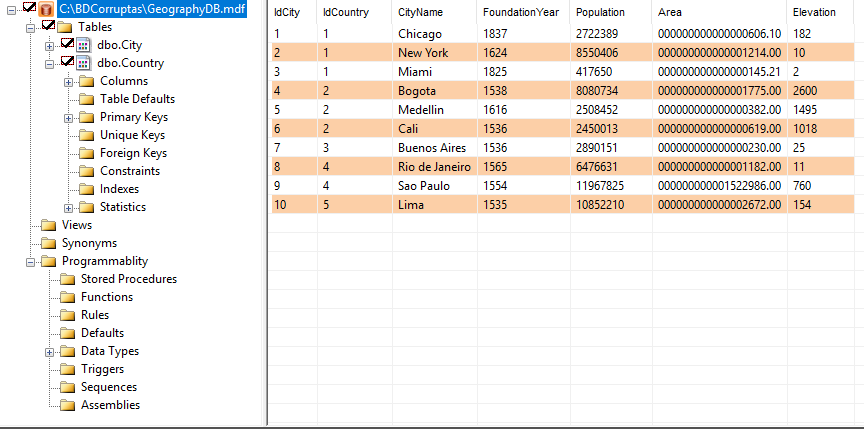
Ver Figura 22 – Registro recuperados de la tabla City.
Continuamos con el siguiente paso que se encuentra descrito en la Figura 15, guardar la reparación de la base datos. Para eso damos click en el menú archivo opción Guardar. Al dar click en guardar estaremos garantizando el éxito del proceso de reparación de la base de datos y nos muestra una ventana preguntándonos que como queremos salvar esta recuperación si como una base de datos MSSQL, un archivo CSV, un archivo HTML o un archivo XLS. Para nuestro ejemplo seleccionaremos MSSQL. Ver Figura 23.
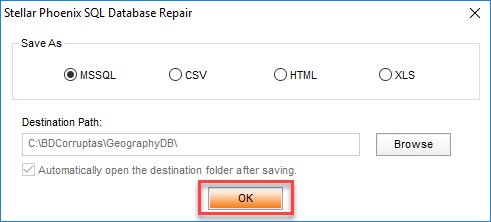 Ver Figura 23 – Formatos de archivos para guardar la recuperación.
Ver Figura 23 – Formatos de archivos para guardar la recuperación.
Como seleccionamos que guardara como una base de datos MSSQL el software nos presenta dos formas:
Nueva base de datos: En esta opción el software nos crea una base de datos nueva totalmente recuperada.
Para esto nos pide que selecciones la instancia del servidor de SQL Server donde queremos que nos cree la nueva base de datos y la ubicación donde almacenaremos el nuevo archivo MDF. En este caso seleccionaremos la ubicación por defecto. Damos click en Conectar. Ver Figura 24.

Ver Figura 24 – Opción de guardar, creando una nueva Base de Datos.
El software empieza a establecer la conexión y ejecutar los respectivos scripts con todos los objetos de la base de datos incluyendo los que estaban corruptos. Para verificar entramos a Management Studio, nos conectamos a nuestra instancia donde tenemos la base de datos original llamada GeographyDB que fue la que creamos a través de los scripts y posteriormente corrompimos y la nueva base de datos llamada Recovered_GeogaraphyDB que creo el software cuando guardamos la reparación.
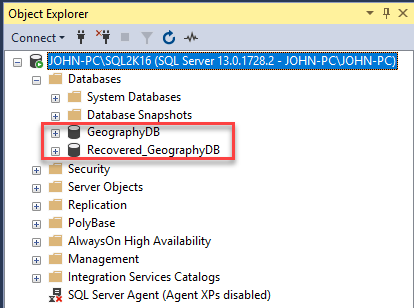
Ver Figura 25 – Base de datos original corrupta y base de datos nueva reparada.
Ahora verificamos que este la información de la tabla City en la nueva base de datos. Ver Figura 26.
-- Verificamos los registros de la tabla Country en la nueva BD
SELECT * FROM [Recovered_GeographyDB].[dbo].[City];
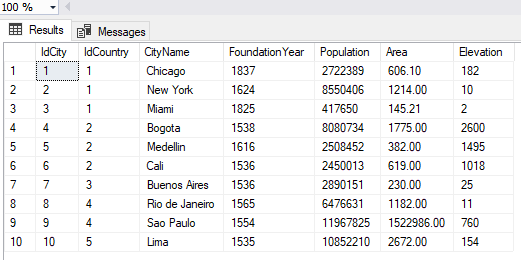
Figura 26. – Registros en la tabla City de la nueva base de datos.
Live database: En esta opción lo que hace el software es que crea nuevos objetos totalmente recuperados. En nuestro ejemplo nos creara una nueva tabla para City y para Country, con la información recuperada. Damos click en conectar. Ver Figura 27.
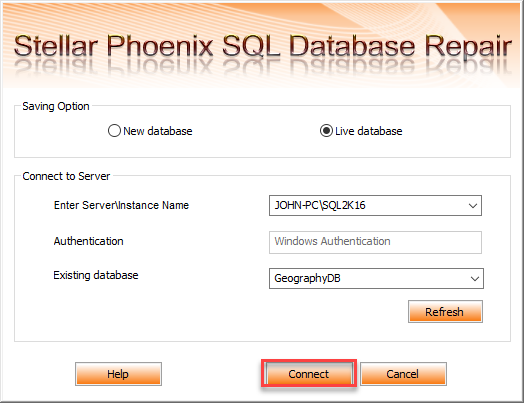
Ver Figura 27. – Opción de guardar, creando los objetos en una Base de Datos existente.
El software empieza a establecer la conexión y ejecutar los respectivos scripts con todos los objetos de la base de datos incluyendo los que estaban corruptos. Para verificar entramos a Management Studio, nos conectamos a nuestra instancia donde tenemos la base de datos original llamada GeographyDB que fue la que creamos a través de los scripts y posteriormente corrompimos con nuevas tablas para City y Country. Ver Figura 28.
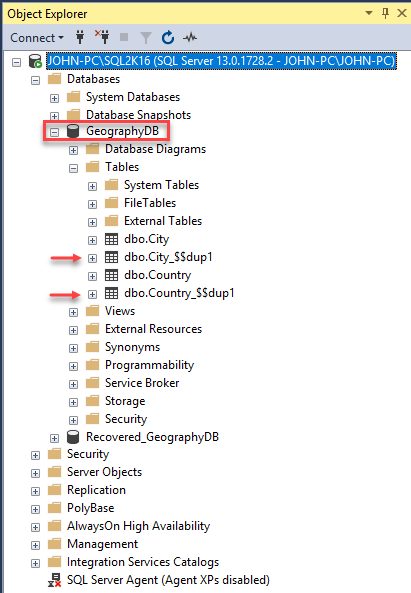
Ver Figura 28 – Base de datos original corrupta con nuevas tablas para City y Country.
Ahora verificamos que este la información que teníamos en la tabla City en la nueva tabla City_$$dup1 en la base de datos original GeographyDB. Ver Figura 29
-- Verificamos los registros de la tabla City_$$dup1 en la BD original
SELECT * FROM [GeographyDB].[dbo].[City_$$dup1]
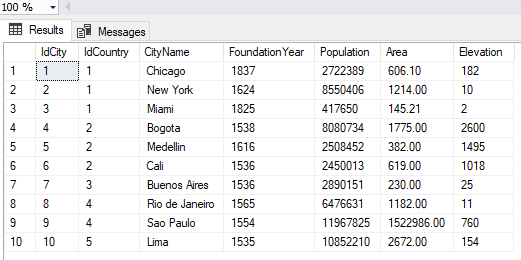
Figura 29. – Registros en la tabla City_$$dup1 de la nueva base de datos.
Con esto compramos que el software Stellar Phoenix SQL Database Repair funciona correctamente y nos recupera las bases de datos corruptas.
Versión gratuita de evaluación
Los invito a que descargue la versión gratuita de evaluación de Stellar Phoenix SQL Database Repair. Con la descarga Gratuita podrá comprobar la vista previa de los objetos recuperables de tu base de datos. Para guardar la base de datos recuperada en tu ordenador tendrás que comprar el programa.

Quiero agradecer a Priyanka Chouhan de Stellar Information Technology Pvt. Ltd por la invitación para hacer esta revisión del producto Stellar Phoenix SQL Database Repair.
Espero este artículo sea de utilidad.
Saludos,